
Challenges in Natural Language Processing – A Detailed Overview

Artificial intelligence has made outstanding strides in mimicking different human languages. However, it still falls short in one of the many areas – giving more human-like responses. Sarcasm, irony, and context are a few examples that AI is still working on. Questions like “Which came first, the chicken or the egg?” are another example that great NLP models still face challenges in solving.
Natural Language Processing (NLP) is an advanced technology that helps humans and machines communicate in the rapidly shifting area of artificial intelligence. Just like any other AI integration development solution, Natural Language Processing faces many challenges. Difficulties like interpreting the context, handling ambiguity, and understanding multiple languages hamper its performance.
Natural Language Processing is our future, not just because every tech leader says that nowadays, but because its potential is vast. It still has a lot of technological advancements to be made in chatbots, voice assistants, and translation models. So, it is important for us, as everyday users, to perceive the challenges in NLP in order to leverage its potential efficiently. Understanding these difficulties will enable us to explore modern-day natural language processing (NLP) and realize its potential to revolutionize human-machine communication, affecting everything from complex data analysis to automated customer support.
In this blog, we will look at the top 7 obstacles that NLP models face these days. We will also share ways to overcome these challenges in NLP. Let’s get started.
What is Natural Language Processing?
Natural language processing is a branch of artificial intelligence that helps systems perceive, decipher, and produce meaningful and readable texts. It then allows machines to communicate with humans through text and speech-based data.
Natural language processing involves tokenizing the texts. It means breaking the text up into discrete units, which could be words, phrases, or characters. This is the initial phase of NLP, a preprocessing and cleaning step before using the Natural Language Processing technique.
Some areas where NLP is widely used are machine translation, sentiment analysis, healthcare, finance, customer service, and the extraction of useful information from text data. NLP is also utilized in language modeling and text generation.
Moreover, answers to the questions can be obtained by using the Natural Processing technique. To address their text-related issues, numerous businesses employ Natural Language Processing techniques. ChatGPT and Google Bard are examples of tools that use natural language processing to answer user queries after being trained on a sizable corpus of test data.
Primary Challenges in NLP Models
The complexity and diversity of human language present some difficulties for natural language processing (NLP). Let’s talk about NLP’s main challenges:
| Challenges in NLP | Solutions |
| Language & Context Differences | Use contextual embeddings, semantic analysis, and syntax analysis |
| Training Data | Collect and preprocess high-quality, diverse data, and use data augmentation |
| Resource Requirements & Development Time | Optimize algorithms, use pre-existing tools, and use GPUs/TPUs for training |
| Facing “Phrasing Ambiguities” in NLP | Use contextual understanding, semantic analysis, and syntactic analysis |
| Grammatical Errors & Misspellings | Apply spell-checking, text normalization, and tokenization techniques |
| Reducing Innate Biases in NLP Algorithms | Employ diverse data collection, fairness-aware training, and model auditing |
| Words with Various Meanings | Use semantic analysis, domain-specific knowledge, and knowledge graphs/ontologies |
Language & Context Differences
Human language and its comprehension are complex and multifaceted, and people speak a wide variety of languages. The world is home to thousands of different human languages, each with its own unique vocabulary, grammar, and cultural quirks.
Humans are not able to comprehend every language, and human language is very productive. Ambiguity exists in natural language because the same words and phrases can have multiple meanings.
Human languages have intricate grammatical rules and syntactic structures. Word order, verb, conjugation, tense, aspect, and agreement are among the rules. They have rich semantic content that enables speakers to express a variety of meanings with words and sentences. The pragmatics of natural language refers to how language can be employed contextually to achieve communication objectives. Lexical change is one process that causes the human language to change over time.
Training Data
Training data is a carefully selected set of input-output pairs, where the output is the label or target that corresponds to the input. This is the data’s features or attributes. Both the features (inputs) and the labels that go with them (outputs) make up training data.
Labels for NLP could be sentiments, categories, or any other pertinent annotations, while features could be text data. It facilitates the model’s ability to extrapolate patterns from the training set to new, untested data in order to generate predictions or classifications.
Resource Requirements & Development Time
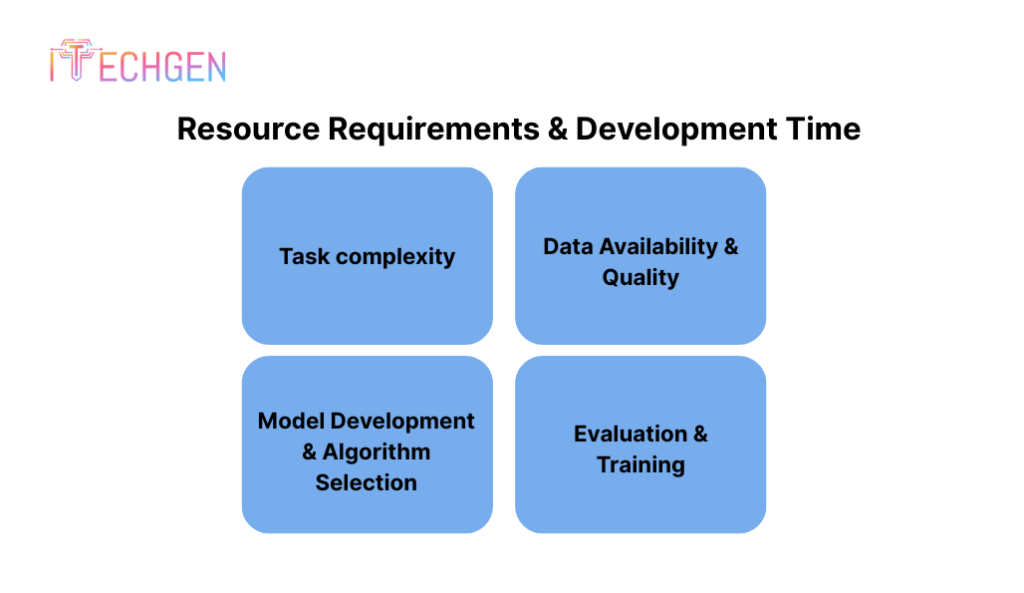
The complexity of the task, the volume and caliber of the data, the availability of pre-existing tools and libraries, and the team of experts involved are some of the variables that affect the development time and resource requirements for Natural Language Processing (NLP) projects.
Here are a few important points:
- Task complexity: Less time may be needed for tasks like text classification or sentiment analysis than for more complicated ones like machine translation or question answering.
- Data availability and quality: High-quality annotated data is necessary for Natural Language Processing models. Large text dataset collection, annotation, and preprocessing can take a lot of time and resources, particularly for tasks requiring precise annotations or specialized domain knowledge.
- Model development and algorithm selection: Selecting the best machine learning algorithms for tasks involving natural language processing can be challenging.
- Evaluation and training: It necessitates time for iterative algorithm training as well as strong computational resources, such as GPUs or TPUs. It’s also critical to assess the model’s performance using appropriate metrics and validation methods to ensure the caliber of the output.
Facing “Phrasing Ambiguities” in NLP
With the inherent complexity of human languages, navigating phrasing ambiguities in NLP is an essential part of the process. Phrasing ambiguities are caused when a phrase can be interpreted in a variety of ways, leaving the meaning unclear.
- Contextual Understanding: Contextual information such as prior sentences, topic focus, or conversational cues can help you navigate phrasing ambiguities in natural language processing.
- Semantic Analysis: Words, lexical relationships, and semantic roles are used to analyze the semantic text’s content and determine its meaning. Phrasing ambiguities can be resolved with the use of tools like semantics role labeling and word sense disambiguation.
- Syntactic Analysis: Using grammatical relationships and syntactic patterns, the sentence’s syntactic structure is examined to determine a potential evaluation.
- Pragmatic analysis: NLP models still can’t fully use pragmatic elements like the speaker’s intentions and implicatures to deduce a phrase’s meaning. The pragmatic context must be understood in order to perform this analysis.
- Statistical techniques: To identify patterns in data and forecast the input phrase, statistical techniques and machine learning development models are employed.
Grammatical Errors & Misspellings
Overcoming misspellings and grammatical errors is one of the fundamental challenges in NLP. Various types of linguistic noise can affect the accuracy of understanding.
Here are some essential tips for fixing grammatical and misspelling errors in natural language processing:
- Spell checking: Use dictionaries and spell-check algorithms to identify and fix misspelled words.
- Text normalization: It is the process of transforming the text into a standard format, which may include tasks like reducing the text’s capitalization, eliminating punctuation and special characters, and enlarging contractions.
- Tokenization: Tokenization techniques are used to divide the text into discrete tokens. This method makes it possible to locate and separate grammatical errors and misspelled words and form correct phrases.
- Language Models: Language models can be trained on a vast corpus of data to predict the likelihood of what could come next, which may or may not be correct irrespective of the context.
Reducing Innate Biases in NLP Algorithms
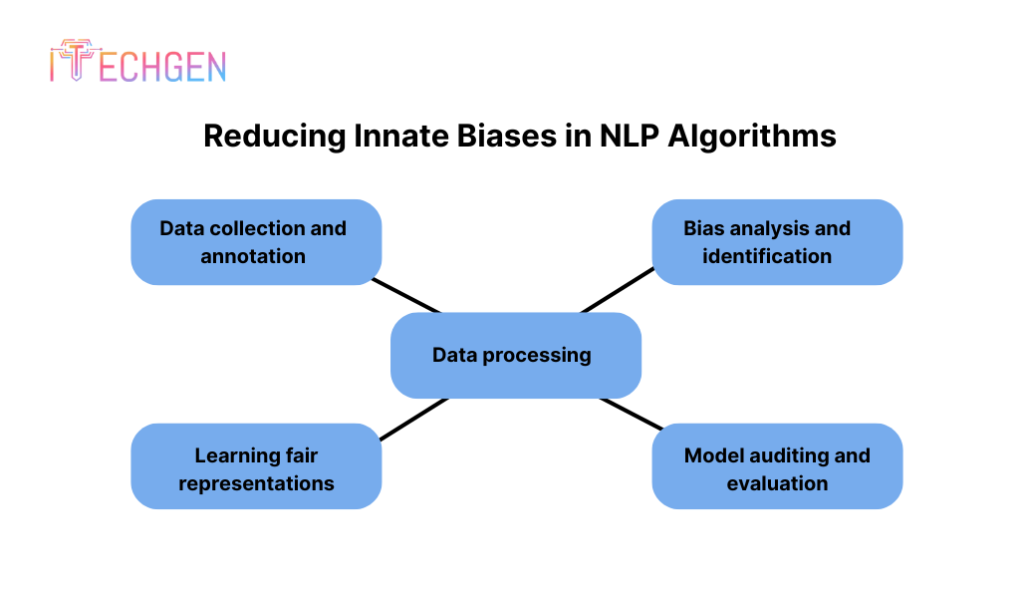
Decreasing innate biases in NLP algorithms is an essential step in ensuring fairness, equity, and inclusivity in applications involving natural language processing, especially where AI in business models is explicitly used.
The following are important guidelines for mitigating biases in NLP algorithms.
- Data collection and annotation: Verifying that the training data used to create NLP algorithms is representative, diverse, and bias-free is crucial.
- Bias analysis and identification: Applying the bias identification and analysis technique to training data will help detect biases based on demographic characteristics like age, gender, and race.
- Data processing: The most crucial step in training data to reduce biases is data preprocessing, which includes balancing class distributions, enhancing underrepresented samples, and debiasing word embeddings.
- Learning fair representations: In order to protect sensitive data like gender or race, Natural Language Processing models are trained to learn fair representations that are invariant.
- Model auditing and evaluation: Metrics and audits are used to assess the fairness and biases of NLP models. To identify and address inherent biases in NLP algorithms, NLP models are tested on a variety of datasets and subjected to post-hoc analyses.
Words with Various Meanings
Due to their ambiguity, words with multiple meanings present a lexical challenge in natural language processing. These words are either homonymous or polysemous and have distinct meanings depending on the context in which they are used.
Here are some key points to represent the lexical challenges posed by these words:
- Semantic analysis: Use semantic analysis methods to determine the word’s underlying meaning in different contexts. Semantic representations that can identify semantic relatedness and similarity between various word senses are called word embeddings for semantic networks.
- Specific domain knowledge: In NLP tasks, it is crucial to have unique domain knowledge that can be useful in offering useful context and constraints for figuring out the word’s correct context.
- Multi-word expressions: To distinguish a word with multiple meanings, the meaning of the entire sentence or phrase is carefully examined.
- Knowledge Graphs and Ontologies: Use ontologies and knowledge graphs to determine the semantic connections between various word contexts.
How to Overcome NLP Challenges
Overcoming NLP challenges requires a mixture of advanced tech, domain expertise, and a carefully-driven approach. Here are some tips for overcoming the challenges in NLP:
Quantity and Quality of Data: NLP algorithms are trained using diverse and high-quality data. Techniques like data synthesis, crowdsourcing, and data augmentation can be used to address data scarcity issues.
Ambiguity: It is necessary to train the NLP algorithm to distinguish between different words and phrases.
Learning new words: Vocabulary expansion, character-level modeling, and tokenization are some of the methods used to deal with words that are not part of the standard vocabulary.
Absence of Annotated Data: With little labeled data, methods like transfer learning and pre-training can be applied to apply knowledge from large datasets to particular tasks.
Final Words
Despite various challenges in NLP, its true potential lies not just in language processing, but genuinely comprehending it. It is something that continues to flourish with every obstacle and breakthrough. Consistent improvements in AI models, machine learning development, and research are the keys to overcoming the challenges mentioned in the blog. For businesses and industries looking to adopt NLP, understanding and tackling these challenges is crucial to unlocking its full potential.
This is where iTechGen comes in to help you improve communication with your audience using NLP-based models. Partner with us to leverage the full capabilities of natural language processing and start your journey of growth and innovation in the digital age.

Pankaj Arora (Founder & CEO)
Pankaj Arora is the Founder & CEO of iTechGen, a visionary leader with a deep passion for AI and technology. With extensive industry experience, he shares expert insights through his blogs, helping businesses harness the power of AI to drive innovation and success. Committed to delivering customer-first solutions, Pankaj emphasizes quality and real-world impact in all his endeavors. When not leading iTechGen, he explores emerging technologies and inspires others with his thought leadership. Follow his blogs for actionable strategies to accelerate your digital transformation and business growth.
View More About Pankaj Arora